Provision target deployment infrastructure dynamically with Terraform
You can use Terraform in Harness CD pipeline stages for ad hoc provisioning or to provision the target deployment infrastructure for the stage.
This topic provides a brief overview of the steps involved in provisioning a CD stage's target deployment infrastructure using the Terraform Plan and Apply steps.
This topic also covers some important requirements.
Terraform dynamic infrastructure provisioning summary
Setting up dynamic provisioning involves adding Terraform scripts to the stage Environment settings that provision the pipeline stage's target infrastructure.
Next, you map specific, required script outputs to the Harness Infrastructure Definition for the stage, such as the target namespace.
During deployment, Harness provisions the target deployment infrastructure and then the stage's Execution steps deploy to the provisioned infrastructure.
Dynamic provisioning steps for different deployment types
Each of the deployment types Harness supports (Kubernetes, AWS ECS, etc.) require that you map different Terraform script outputs to the Harness infrastructure settings in the pipeline stage.
To see how to set up dynamic provisioning for each deployment type, go to the following topics:
- Kubernetes infrastructure
- The Kubernetes infrastructure is also used for Helm, Native Helm, and Kustomize deployment types.
- Azure Web Apps
- AWS ASG
- AWS ECS
- AWS Lambda
- Spot Elastigroup
- Google Cloud Functions
- Serverless.com framework for AWS Lambda
- Tanzu Application Services
- VM deployments using SSH
- Windows VM deployments using WinRM
Important: install Terraform on delegates
Terraform must be installed on the Delegate to use a Harness Terraform Provisioner. You can install Terraform manually or use the INIT_SCRIPT environment variable in the Delegate YAML.
See Build custom delegate images with third-party tools.
#!/bin/bash
# Check if microdnf is installed
if ! command -v microdnf &> /dev/null
then
echo "microdnf could not be found. Installing..."
yum install -y microdnf
fi
# Update package cache
microdnf update
# Install Terraform
microdnf install -y terraform
Dynamic provisioning steps
These steps assume you've created a Harness CD stage before. If Harness CD is new to you, see Kubernetes CD Quickstart.
We'll start in the stage's Infrastructure section because the Service settings of the stage don't have specific settings for Terraform provisioning. The Service manifests and artifacts will be deployed to the infrastructure provisioned by Harness and Terraform.
-
In the CD stage, click Infrastructure. If you haven't already specified your Environment, and selected the Infrastructure Definition, do so.
The type of Infrastructure Definition you select determines what Terraform outputs you'll need to map later.
-
In Dynamic provisioning, click Provision your infrastructure dynamically during the execution of your pipeline.
The default Terraform provisioning steps appear:
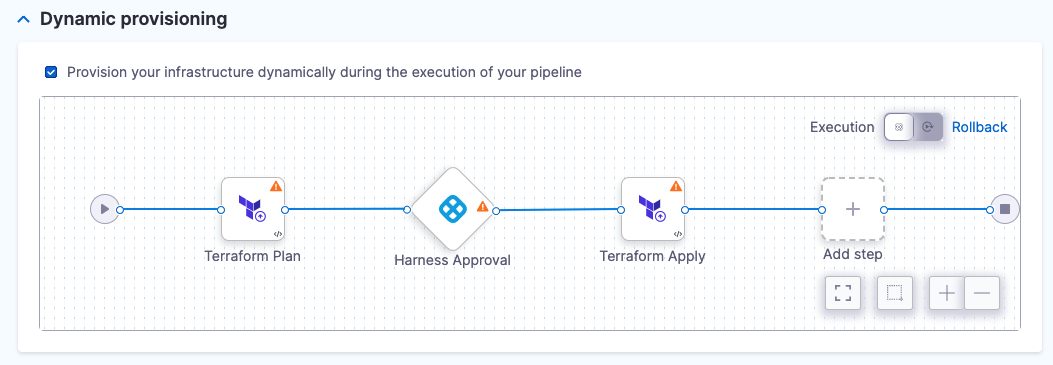
Harness automatically adds the Terraform Plan, Harness Approval, and Terraform Apply steps. You can change these steps, but plan, approve, and apply is the most common process. We use that process in our Terraform documentation.
Terraform Plan step
The Terraform Plan step is where you connect Harness to your repo and add your Terraform scripts.
Name
- In Name, enter a name for the step, for example, plan.
Harness will create an Entity Id using the name. The Id is very important. It's used to refer to settings in this step.
For example, if the Id of the stage is terraform and the Id of the step is plan, and you want to echo its timeout setting, you would use:
<+pipeline.stages.Terraform.spec.infrastructure.infrastructureDefinition.provisioner.steps.plan.timeout>
Timeout
- In Timeout, enter how long Harness should wait to complete the Terraform Plan step before failing the step.
Command
- In Command, select Apply. Even though you are only running a Terraform plan in this step, you identify that this step can be used with a Terraform Apply step later.
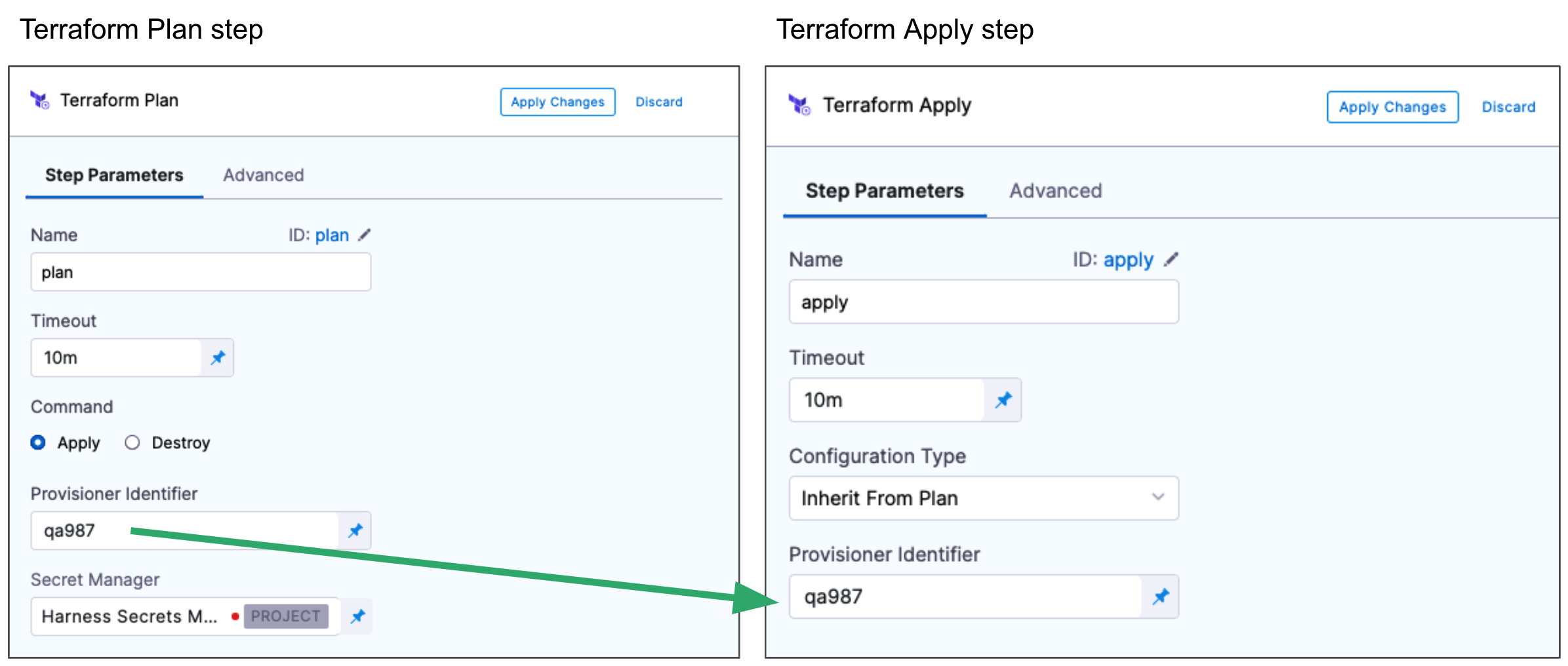
Provisioner Identifier
- Enter a unique value in Provisioner Identifier.
The Provisioner Identifier identifies the provisioning done in this step. You use the Provisioner Identifier in additional steps to refer to the provisioning done in this step.
The most common use of Provisioner Identifier is between the Terraform Plan and Terraform Apply steps. To have the Terraform Apply step apply the provisioning from this Terraform Plan step, you use the same Provisioner Identifier in both steps.
Provisioner Identifier Scope
The Provisioner Identifier is a Project-wide setting. You can reference it across Pipelines in the same Project.
For this reason, it's important that all your Project members know the Provisioner Identifiers. This will prevent one member building a Pipeline from accidentally impacting the provisioning of another member's Pipeline.
Secret Manager
- Select a Secrets Manager to use for encrypting/decrypting and saving the Terraform plan file.
See Harness Secrets Manager Overview.
A Terraform plan is a sensitive file that could be misused to alter resources if someone has access to it. Harness avoids this issue by never passing the Terraform plan file as plain text.
Harness only passes the Terraform plan between the Harness Manager and Delegate as an encrypted file using a Secrets Manager.
Some third-party secret managers, such as HashiCorp Vault, Azure Key Vault, and AWS Secrets Manager, have a maximum secret size limitation. If the size of the secret you want to store exceeds this limit, an error will be thrown by the corresponding third-party system. Therefore, it's crucial to check the maximum secret size supported by your chosen secret manager and ensure that your secrets are within the size limit.
In contrast, key management services like Google Cloud KMS or AWS KMS do not have the same limitation as they are primarily designed for managing encryption keys, not arbitrary secret data. However, it's still essential to check the specific limitations of your chosen key management service and ensure that your secrets meet their requirements.
When designing your secret management strategy and selecting a secret management solution, consider the maximum secret size limit and other limitations that may affect your use case. You may need to choose a secret manager that can handle larger secret sizes or find alternative strategies for managing secrets that exceed the maximum size limit of your chosen secret manager.
When the terraform plan command runs on the Harness Delegate, the Delegate encrypts the plan and saves it to the Secrets Manager you selected. The encrypted data is passed to the Harness Manager.
When the plan is applied, the Harness Manager passes the encrypted data to the Delegate.
The Delegate decrypts the encrypted plan and applies it using the terraform apply command.
Please enable the `CDS_TERRAFORM_TERRAGRUNT_PLAN_ENCRYPTION_ON_MANAGER_NG` feature flag if the default Harness secret manager is selected for the encryption/decryption of Terraform plans. Contact [Harness Support](mailto:support@harness.io) to enable the feature flag.
Configuration File Repository
Configuration File Repository is where the Terraform script and files you want to use are located.
Here, you'll add a connection to the Terraform script repo.
-
Click Specify Config File or edit icon.
The Terraform Config File Store settings appear.
-
Click the provider where your files are hosted.

-
Select or create a Connector for your repo. For steps, see Connect to a Git Repo, Artifactory Connector Settings Reference (see Artifactory with Terraform Scripts and Variable Definitions (.tfvars) Files) or AWS Connector Settings Reference
If you're simply experimenting, you can use HashiCorp's Kubernetes repo.
Git providers
-
In Git Fetch Type, select Latest from Branch or Specific Commit ID. When you run the Pipeline, Harness will fetch the script from the repo.
-
Specific Commit ID also supports Git tags.If you think the script might change often, you might want to use Specific Commit ID. For example, if you are going to be fetching the script multiple times in your Pipeline, Harness will fetch the script each time. If you select Latest from Branch and the branch changes between fetches, different scripts are run.
-
In Branch, enter the name of the branch to use.
-
In Folder Path, enter the path from the root of the repo to the folder containing the script.
For example, here's a Terraform script repo, the Harness Connector to the repo, and the Config Files settings for the branch and folder path:

-
Click Submit.
Your Terraform Plan step is now ready. You can now configure the Terraform Apply step that will inherit the Terraform script and settings from this Terraform Plan step.
You can jump ahead to the Terraform Apply step below. The following sections cover common Terraform Plan step options.
Artifactory
See Artifactory Connector Settings Reference (see Artifactory with Terraform Scripts and Variable Definitions (.tfvars) Files).
AWS S3
-
In Region, select the region where your bucket is stored.
-
In Bucket, select the bucket where your Terraform files are stored (all buckets from the selected region that are available to the connector will be fetched).
-
In Folder Path, enter the path from the root of the repo to the folder containing the script.
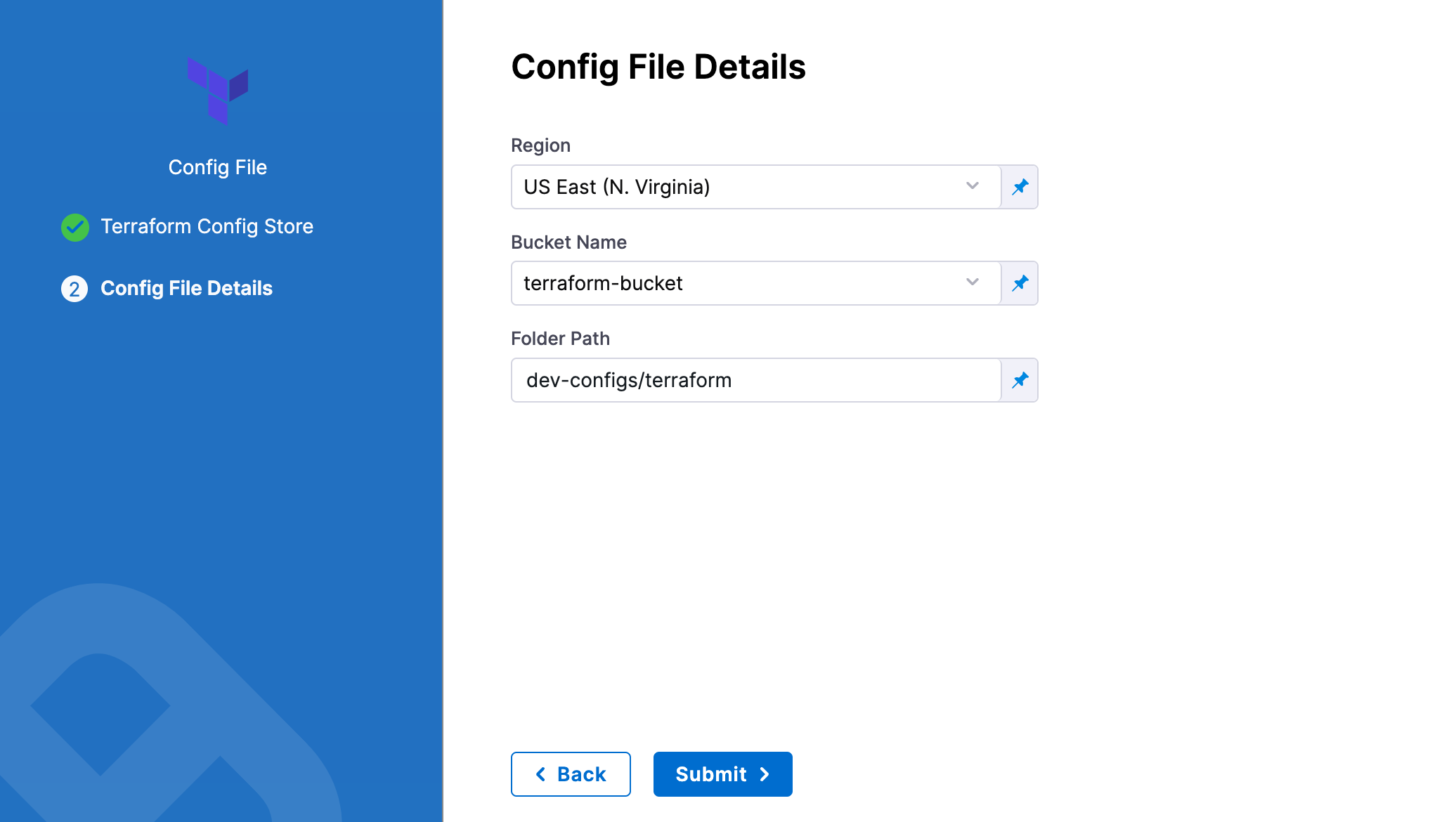
Harness will fetch all files from the specified folder.
Source Module
When you set up the file repo in Configuration File Repository, you use a Harness Connector to connect to the repo where the Terraform scripts are located.
Some scripts will reference module sources in other repos and Harness will pull the source code for the desired child module at runtime (during terraform init).
In Source Module, you can select Use Connector credentials to have Harness use the credentials of the Connector to pull the source code for the desired child module(s).
If you do not select Use Connector credentials, Terraform will use the credentials that have been set up in the system.
The Use Connector credentials setting is limited to Harness Git Connectors using SSH authentication (not HTTPS) and a token.
When configuring the SSH key for the connector, exporting an SSH key with a passphrase for the module source is not supported. Configure an SSH Key without the passphrase.
Here are some syntax examples to reference the Terraform module using the SSH protocol:
source = "git@github.com:your-username/your-private-module.git"
## Workspace
Harness supports Terraform [workspaces](https://www.terraform.io/docs/state/workspaces.html). A Terraform workspace is a logical representation of one your infrastructures, such as Dev, QA, Stage, Production.
Workspaces are useful when testing changes before moving to a production infrastructure. To test the changes, you create separate workspaces for Dev and Production.
A workspace is really a different state file. Each workspace isolates its state from other workspaces. For more information, see [When to use Multiple Workspaces](https://www.terraform.io/docs/state/workspaces.html#when-to-use-multiple-workspaces) from Hashicorp.
Here's an example script where a local value names two workspaces, **default** and **production**, and associates different instance counts with each:
```json
locals {
counts = {
"default"=1
"production"=3
}
}
resource "aws_instance" "my_service" {
ami="ami-7b4d7900"
instance_type="t2.micro"
count="${lookup(local.counts, terraform.workspace, 2)}"
tags {
Name = "${terraform.workspace}"
}
}
In the workspace interpolation sequence, you can see the count is assigned by applying it to the Terraform workspace variable (terraform.workspace) and that the tag is applied using the variable also.
Harness will pass the workspace name you provide to the terraform.workspace variable, thus determining the count. If you provide the name production, the count will be 3.
In the Workspace setting, you can simply select the name of the workspace to use.
You can also use a stage variable in Workspace.
Later, when the Pipeline is deployed, you specify the value for the stage variable and it is used in Workspace.
This allows you to specify a different workspace name each time the Pipeline is run.
You can even set a Harness Trigger where you can set the workspace name used in Workspace.
Terraform Var Files
The Terraform Var Files section is for entering and/or linking to Terraform script Input variables.
You can use inline or remote var files.
Harness supports all Terraform input types and values.
Inline Variables
You can add inline variables just like you would in a tfvar file.
- Click Add Terraform Var File, and then click Add Inline.
- The Add Inline Terraform Var File settings appear.
- In Identifier, enter an identifier so you can refer to variables using expressions if needed.
This Identifier is a Harness Identifier, not a Terraform identifier.For example, if the Identifier is myvars you could refer to its content like this:
<+pipeline.stages.MyStage.spec.infrastructure.infrastructureDefinition.provisioner.steps.plan.spec.configuration.varFiles.myvars.spec.content>
Provide the input variables and values for your Terraform script. Harness follows the same format as Terraform.
For example, if your Terraform script has the following:
variable "region" {
type = string
}
In Add Inline Terraform Var File, you could enter:
region = "asia-east1-a"
Inline variable secrets
If you are entering secrets (for credentials, etc.), use Harness secret references in the value of the variable:
secrets_encryption_kms_key = "<+secrets.getValue("org.kms_key")>"
See Add Text Secrets.
Remote variables
You can connect Harness to remote variable files.
- Click Add Terraform Var File, and then click Add Remote.
- Select your provider (GitHub, Artifactory, S3, etc.) and then select or create a Connector to the repo where the files are located. Typically, this is the same repo where your Terraform script is located, so you can use the same Connector.
- Click Continue. The Var File Details settings appear.
Git providers
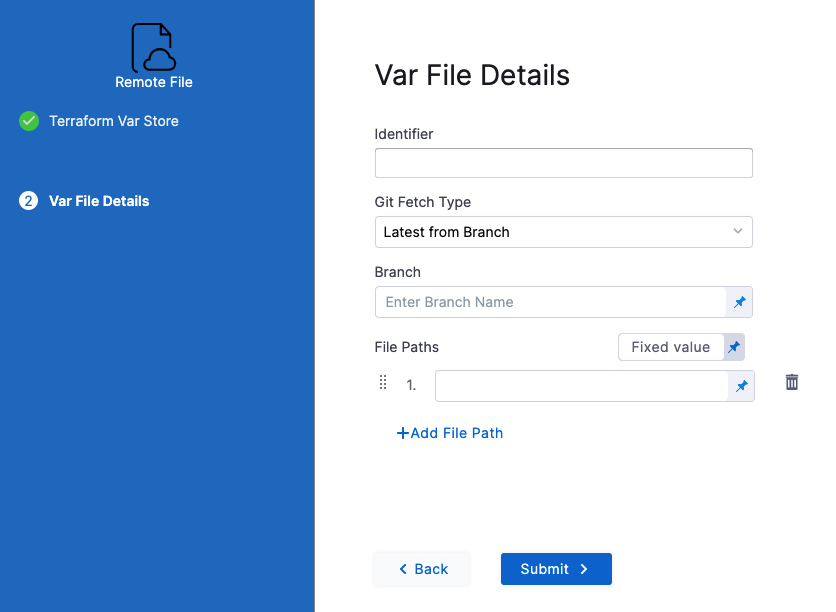
-
In Identifier, enter an identifier so you can refer to variables using expressions if needed.
For example, if the Identifier is myremotevars you could refer to its content like this:
<+pipeline.stages.MyStage.spec.infrastructure.infrastructureDefinition.provisioner.steps.plan.spec.configuration.varFiles.myremotevars.spec.store.spec.paths> -
In Git Fetch Type, select Latest from Branch or Specific Commit ID.
-
In Branch, enter the name of the branch.
-
In File Paths, add one or more file paths from the root of the repo to the variable file.
-
Click Submit. The remote file(s) are added.
Artifactory
See Artifactory Connector Settings Reference (see Artifactory with Terraform Scripts and Variable Definitions (.tfvars) Files).
AWS S3
-
In Identifier, enter an identifier so you can refer to variables using expressions if needed.
-
In Region, select the region where your bucket is stored.
-
In Bucket, select the bucket where your Terraform var files are stored (all buckets from the selected region that are available to the connector will be fetched).
-
In File Paths, add one or more file paths from the root of the bucket to the variable file.
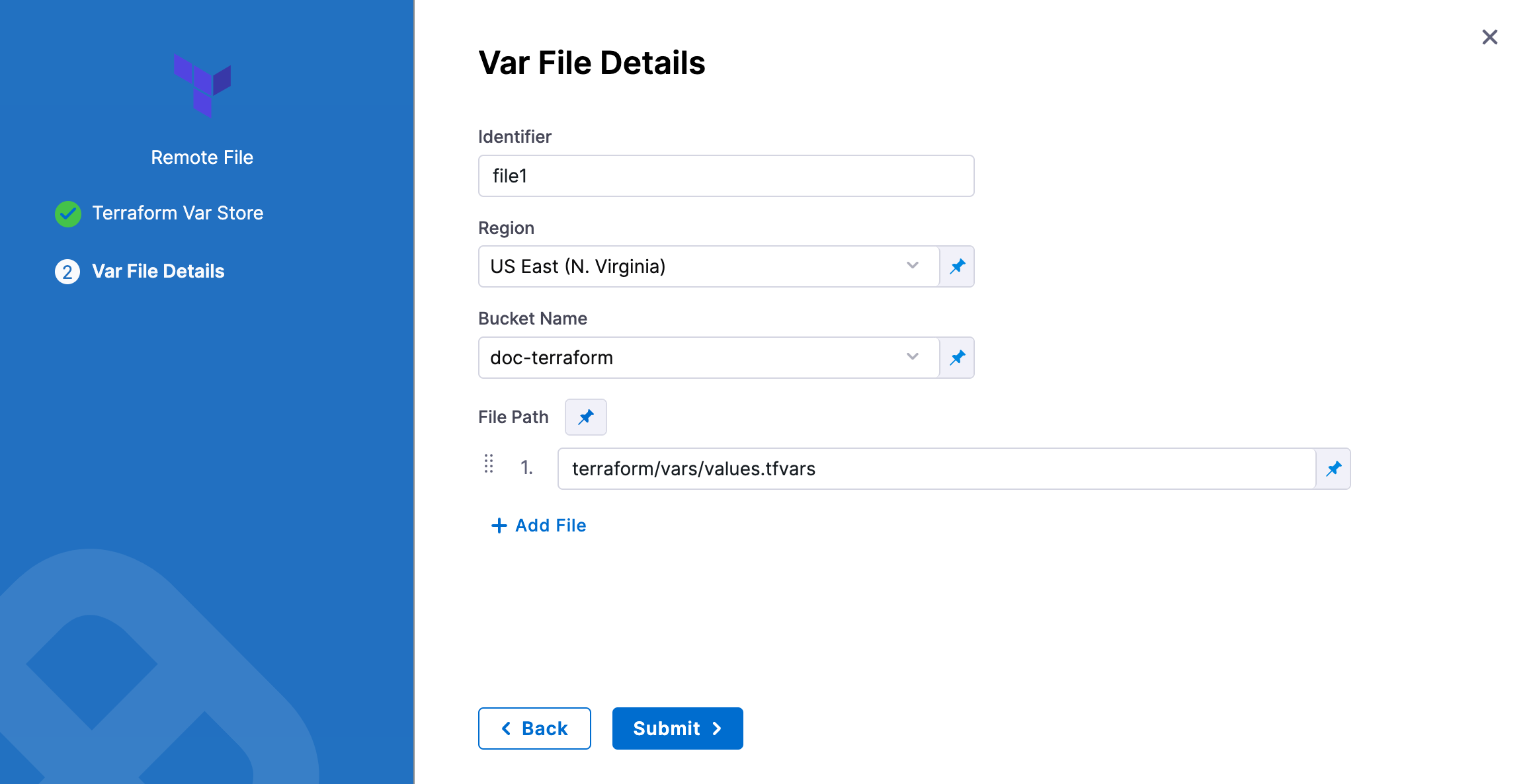
Click Submit. The remote file(s) are added.
Backend Configuration
The Backend Configuration section contains the remote state values.
Enter values for each backend config (remote state variable).
For example, if your config.tf file has the following backend:
terraform {
backend "gcs" {
bucket = "tf-state-prod"
prefix = "terraform/state"
}
}
In Backend Configuration, you provide the required configuration variables for the backend type.
For a remote backend configuration, the variables should be in .tfvars file.
Example:
bucket = "tf-state-prod"
prefix = "terraform/state"
In your Terraform .tf config file, only the definition of the Terraform backend is required:
terraform {
backend "gcs" {}
}
See Configuration variables in Terraform's gcs Standard Backend doc.
You can use Harness secrets for credentials. See Add Text Secrets.
Targets
You can use the Targets setting to target one or more specific modules in your Terraform script, just like using the terraform plan -target command. See Resource Targeting from Terraform.
You simply identify the module using the standard format module.name, like you would using terraform plan -target="module.s3_bucket".
If you have multiple modules in your script and you don't select one in Targets, all modules are used.
Environment Variables
If your Terraform script uses environment variables, you can provide values for those variables here.
For example:
TF_LOG_PATH=./terraform.log
TF_VAR_alist='[1,2,3]'
You can use Harness encrypted text for values. See Add Text Secrets.
Advanced settings
In Advanced, you can use the following options:
Approval step
When you enable dynamic provisioning in a CD Deploy stage's Environment settings, Harness automatically adds the necessary Harness Terraform steps:
- Terraform Plan step: the Terraform Plan step connects Harness to your repo and pulls your Terraform scripts.
- Approval step: Harness adds a Manual Approval step between the Terraform Plan and Terraform Apply steps. You can remove this step or follow the steps in Using Manual Harness Approval Steps in CD Stages to configure the step.
- You can also use a Jira or ServiceNow Approval step.
- Terraform Apply step: the Terraform Apply step simply inherits its configuration from the Terraform Plan step you already configured and applies it.
You must use the same Provisioner Identifier in the Terraform Plan and Terraform Apply steps:

For details on configuring the Terraform steps, go to:
Terraform Rollback
Terraform steps also output the commit Id of config files stored on Git. The outputs are available using expressions.
For example, for a Terraform Apply step with the identifier TerraformApply and with config files, backend config files, and var files stored in git, the expressions would look like this:
- Config files:
<+pipeline.stages.test.spec.execution.steps.TerraformApply.git.revisions.TF_CONFIG_FILES> - Backend config files:
<+pipeline.stages.test.spec.execution.steps.TerraformApply.git.revisions.TF_BACKEND_CONFIG_FILE> - Var file with identifier
varfile1:<+pipeline.stages.test.spec.execution.steps.TerraformApply.git.revisions.varfile1>
The Terraform Rollback step is automatically added to the Rollback section.
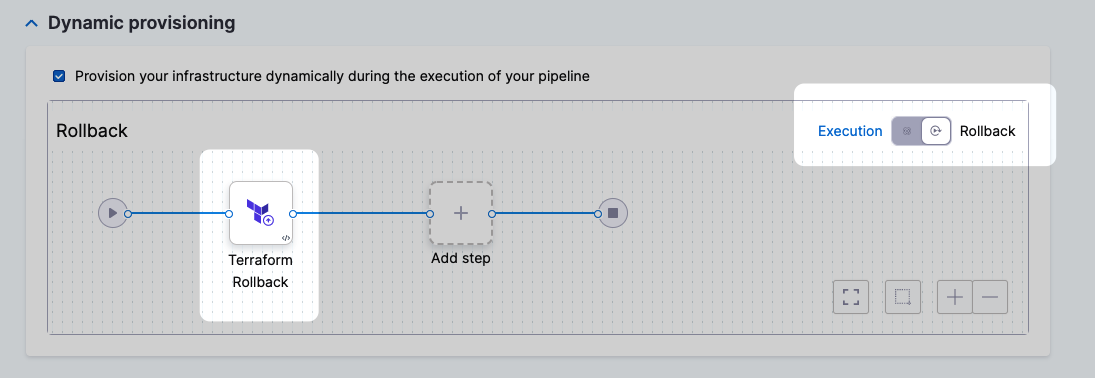
For details on configuring the Terraform Rollback step, go to Terraform Rollback.
When rollback happens, Harness rolls back the provisioned infrastructure to the previous successful version of the Terraform state.
Harness won't increment the serial in the state, but perform a hard rollback to the exact version of the state provided.
Harness determines what to roll back using the Provisioner Identifier.
If you've made these settings expressions, Harness uses the values it obtains at runtime when it evaluates the expression.
Rollback limitations
Let's say you deployed two modules successfully already: module1 and module2. Next, you try to deploy module3, but deployment failed. Harness will roll back to the successful state of module1 and module2.
However, let's look at the situation where module3 succeeds and now you have module1, module2, and module3 deployed. If the next deployment fails, the rollback will only roll back to the Terraform state with module3 deployed. Module1 and module2 weren't in the previous Terraform state, so the rollback excludes them.