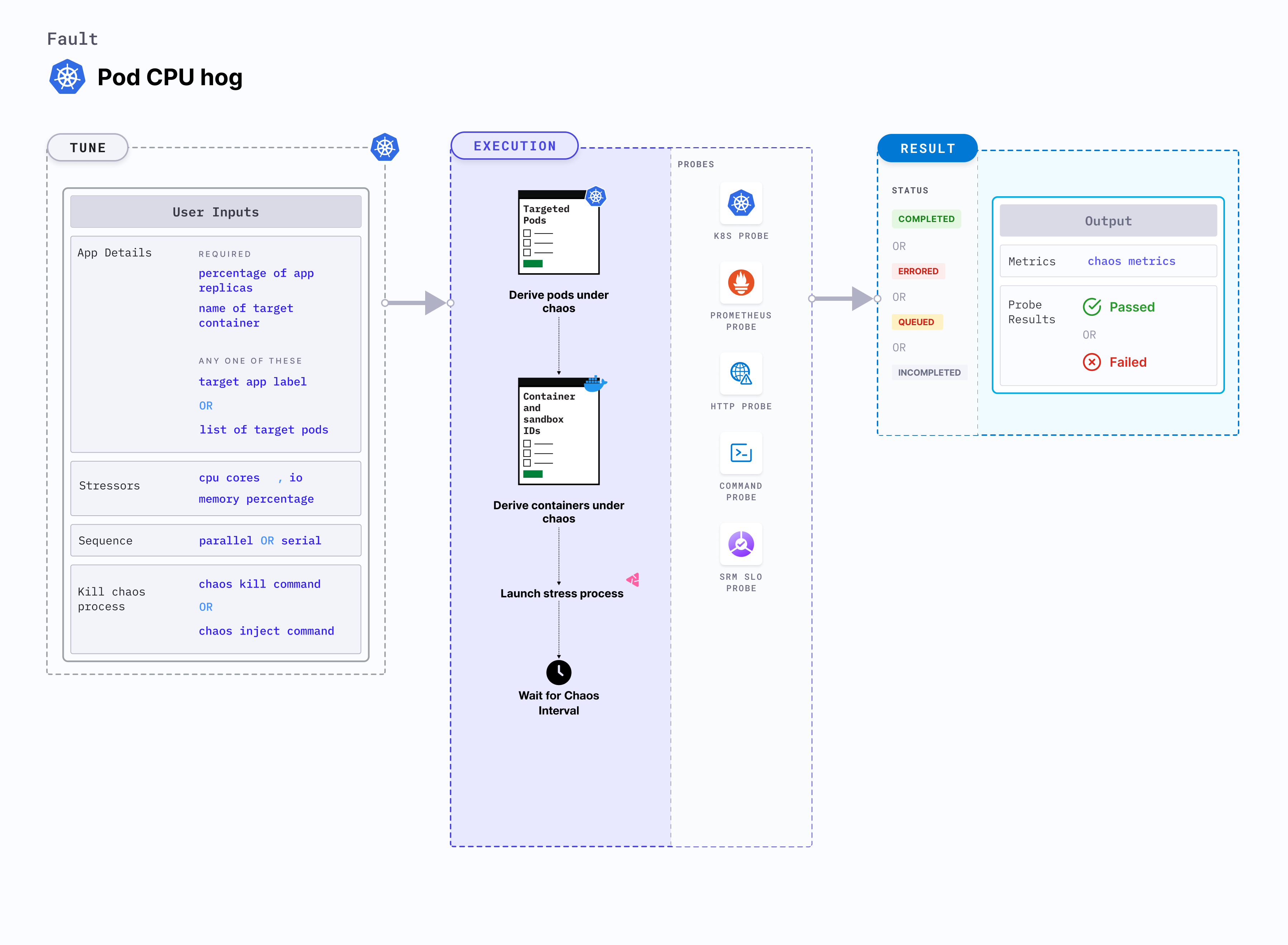
Pod CPU hog
Pod CPU hog is a Kubernetes pod-level chaos fault that excessively consumes CPU resources, resulting in a significant increase in the CPU resource usage of a pod. This fault applies stress on the target pods by smimulating lack of CPU for processes running on the Kubernetes application. This degrades the performance of the application.
Use cases
CPU hog:
- Simulates a situation where the application's CPU resource usage unexpectedly increases.
- Verifies metrics-based horizontal pod autoscaling as well as vertical autoscale, that is, demand based CPU addition.
- Facilitates scalability of the nodes based on the growth beyond budgeted pods.
- Verifies the autopilot functionality of cloud managed clusters.
- Verifies multi-tenant load issues, that is, when the load increases on one container, this does not cause downtime in other containers.
Prerequisites
- Kubernetes > 1.16
- The application pods should be in the running state before and after injecting chaos.
Optional tunables
| Tunable | Description | Notes |
|---|---|---|
| CPU_CORES | Number of CPU cores subject to CPU stress. | Default: 1. For more information, go to CPU cores |
| NODE_LABEL | Node label used to filter the target node if TARGET_NODE environment variable is not set. | It is mutually exclusive with the TARGET_NODE environment variable. If both are provided, the fault uses TARGET_NODE. For more information, go to node label. |
| CPU_LOAD | Perentage of CPU to be consumed. | For more information, go to CPU load |
| TOTAL_CHAOS_DURATION | Duration for which to insert chaos (in seconds). | Default: 60 s. For more information, go to duration of the chaos |
| TARGET_PODS | Comma-separated list of application pod names subject to pod CPU hog. | If this value is not provided, the fault selects the target pods randomly based on provided appLabels. For more information, go to target specific pods |
| TARGET_CONTAINER | Name of the target container under stress. | If this value is not provided, the fault selects the first container of the target pod. For more information, go to target specific container |
| PODS_AFFECTED_PERC | Percentage of total pods to target. Provide numeric values. | Default: 0 (corresponds to 1 replica). For more information, go to pod affected percentage |
| CONTAINER_RUNTIME | Container runtime interface for the cluster | Default: containerd. Supports docker, containerd and crio. For more information, go to container runtime |
| SOCKET_PATH | Path of the containerd or crio or docker socket file. | Default: /run/containerd/containerd.sock. For more information, go to socket path |
| RAMP_TIME | Period to wait before injecting chaos (in seconds). | For example, 30 s. For more information, go to ramp time |
| LIB_IMAGE | Image used to inject chaos. | Default: chaosnative/chaos-go-runner:main-latest. For more information, go to image used by the helper pod. |
| SEQUENCE | Sequence of chaos execution for multiple target pods. | Default: parallel. Supports serial and parallel. For more information, go to sequence of chaos execution |
CPU cores
Number of CPU cores to target. Tune it by using the CPU_CORE environment variable.
The following YAML snippet illustrates the use of this environment variable:
# CPU cores for the stress
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
appinfo:
appns: "default"
applabel: "app=nginx"
appkind: "deployment"
chaosServiceAccount: litmus-admin
experiments:
- name: pod-cpu-hog
spec:
components:
env:
# CPU cores for stress
- name: CPU_CORES
value: '1'
- name: TOTAL_CHAOS_DURATION
value: '60'
CPU load
Percentage of CPU to be consumed. Tune it by using the CPU_LOAD environment variable.
The following YAML snippet illustrates the use of this environment variable:
# CPU load for the stress
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
appinfo:
appns: "default"
applabel: "app=nginx"
appkind: "deployment"
chaosServiceAccount: litmus-admin
experiments:
- name: pod-cpu-hog
spec:
components:
env:
# CPU load in percentage for the stress
- name: CPU_LOAD
value: "100"
# CPU core should be provided as 0 for CPU load
# to work, otherwise it will take CPU core as priority
- name: CPU_CORES
value: "0"
- name: TOTAL_CHAOS_DURATION
value: "60"
Container runtime and socket path
The CONTAINER_RUNTIME and SOCKET_PATH environment variables to set the container runtime and socket file path, respectively.
CONTAINER_RUNTIME: It supportsdocker,containerd, andcrioruntimes. The default value iscontainerd.SOCKET_PATH: It contains path ofcontainerdsocket file by default(/run/containerd/containerd.sock). Fordocker, specify the path as/var/run/docker.sock. Forcrio, specify the path as/var/run/crio/crio.sock.
The following YAML snippet illustrates the use of this environment variable:
## provide the container runtime and socket file path
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
appinfo:
appns: "default"
applabel: "app=nginx"
appkind: "deployment"
chaosServiceAccount: litmus-admin
experiments:
- name: pod-cpu-hog
spec:
components:
env:
# runtime for the container
# supports docker, containerd, crio
- name: CONTAINER_RUNTIME
value: "containerd"
# path of the socket file
- name: SOCKET_PATH
value: "/run/containerd/containerd.sock"
- name: TOTAL_CHAOS_DURATION
VALUE: "60"