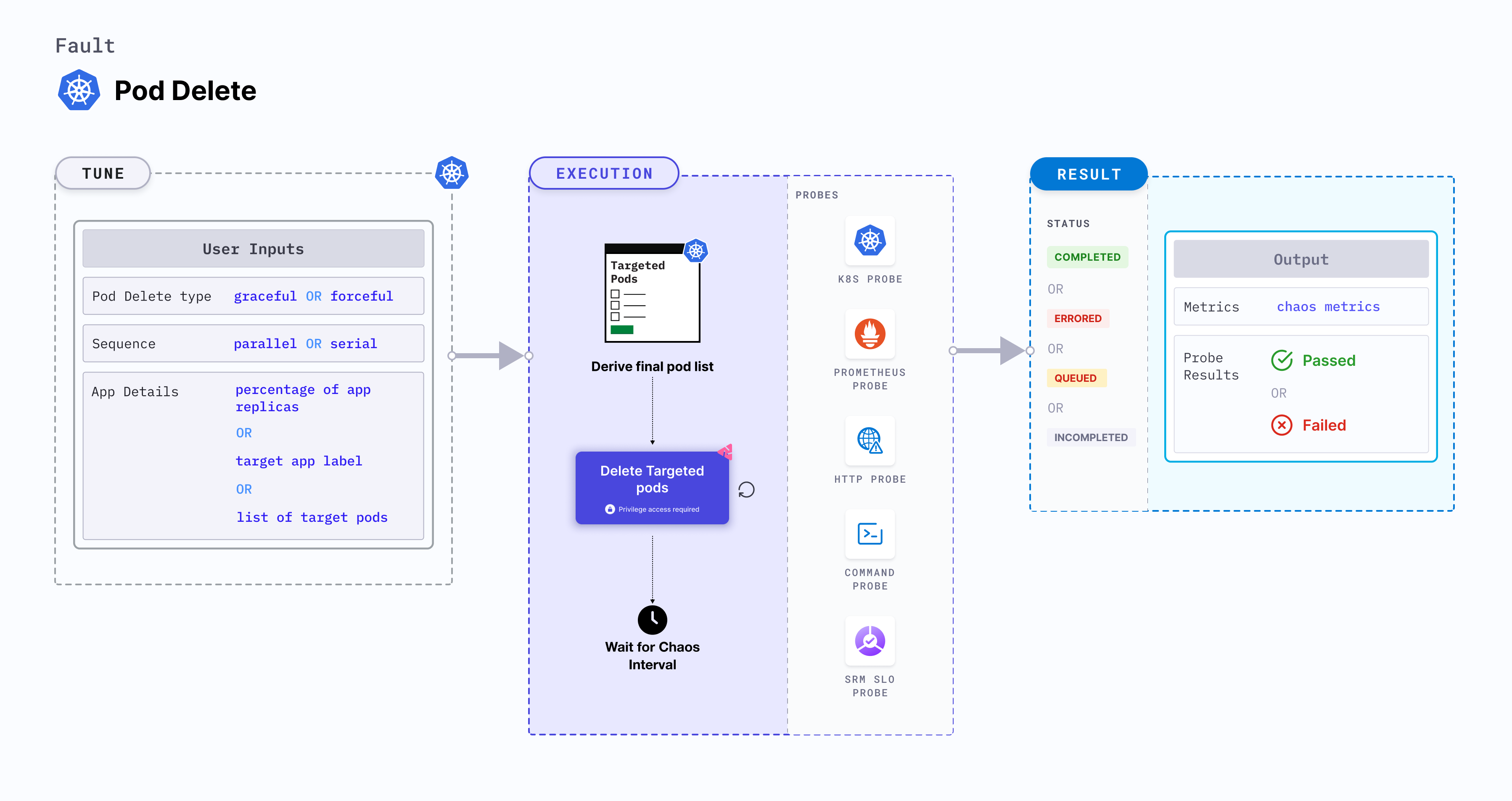
Pod delete
Pod delete is a Kubernetes pod-level chaos fault that causes specific (or random) replicas of an application resource to fail forcibly (or gracefully).
- To ensure smooth usage, applications must have a minimum number of available replicas.
- When the pressure on other replicas increases, the horizontal pod autoscaler scales based on the observed resource utilization.
Use cases
Pod delete:
- Helps check the application's deployment sanity (replica availability and uninterrupted service) and recovery workflow.
- Can be used to verify:
- Disk (or volume) re-attachment times in stateful applications.
- Application start-up times, and readiness probe configuration (health endpoints and delays).
- Adherence to topology constraints (node selectors, tolerations, zone distribution, and affinity (or anti-affinity) policies).
- Proxy registration times in service-mesh environments.
- Post (lifecycle) hooks and termination seconds configuration for the microservices (under active load)- that is, graceful termination handling.
- Resource budgeting on cluster nodes (whether request or limit settings are honored on available nodes for successful schedule).
- Simulates:
- Graceful delete, or rescheduling, of pods as a result of upgrades.
- Forced deletion of pods as a result of eviction.
- Leader-election in complex applications.
Prerequisites
- Kubernetes > 1.16
- The application pods are in the running state before and after chaos injection.
Optional tunables
| Tunable | Description | Notes |
|---|---|---|
| TARGET_CONTAINER | Name of the container subject to pod deletion. | None. For more information, go to target specific container |
| NODE_LABEL | Node label used to filter the target node if TARGET_NODE environment variable is not set. | It is mutually exclusive with the TARGET_NODE environment variable. If both are provided, the fault uses TARGET_NODE. For more information, go to node label. |
| TOTAL_CHAOS_DURATION | Duration for which to insert chaos (in seconds). | Default: 15 s. Overall run duration of the fault may exceed the TOTAL_CHAOS_DURATION by a few minutes. For more information, go to duration of the chaos |
| CHAOS_INTERVAL | Time interval between two successive pod failures (in seconds). | Default: 5 s. For more information, go to chaos interval |
| RANDOMNESS | Introduces randomness into pod deletions with a minimum period defined by CHAOS_INTERVAL | Default: false. Supports true and false. For more information, go to random interval |
| FORCE | Application pod deletion mode. false indicates graceful deletion with the default termination period of 30s, and true indicates an immediate forceful deletion with 0s grace period. | Default: true, with terminationGracePeriodSeconds=0. For more information, go to force delete |
| TARGET_PODS | Comma-separated list of application pod names subject to chaos. | If it is not provided, it selects target pods based on provided appLabels. For more information, go to target specific pods |
| PODS_AFFECTED_PERC | Percentage of total pods to target . Provide numeric values. | Default: 0 (corresponds to 1 replica). For more information, go to pod affected percentage |
| RAMP_TIME | Period to wait before and after injecting chaos (in seconds). | For example, 30 s. For more information, go to ramp time |
| SEQUENCE | Sequence of chaos execution for multiple target pods. | Default: parallel. Supports serial as well. For more information, go to sequence of chaos execution |
Force delete
Specifies if the target pod is deleted forcefully or gracefully. This fault deletes the pod forcefully if FORCE is set to true and gracefully if FORCE is set to false. Tune it by using the FORCE environment variable.
The following YAML snippet illustrates the use of this environment variable:
# tune the deletion of target pods forcefully or gracefully
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
appinfo:
appns: "default"
applabel: "app=nginx"
appkind: "deployment"
chaosServiceAccount: litmus-admin
experiments:
- name: pod-delete
spec:
components:
env:
# provided as true for the force deletion of pod
# supports true and false value
- name: FORCE
value: "true"
- name: TOTAL_CHAOS_DURATION
value: "60"
Random interval
Specifies whether or not to enable randomness in the chaos interval by setting RANDOMNESS environment variable to true. It supports boolean values. The default value is false. Tune it by using the CHAOS_INTERVAL environment variable.
- If
CHAOS_INTERVALis set in the form ofl-rthat is,5-10then it will select a random interval between l and r. - If
CHAOS_INTERVALis set in the form ofvaluethat is,10then it will select a random interval between 0 and value.
The following YAML snippet illustrates the use of this environment variable:
# contains random chaos interval with lower and upper bound of range i.e [l,r]
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
appinfo:
appns: "default"
applabel: "app=nginx"
appkind: "deployment"
chaosServiceAccount: litmus-admin
experiments:
- name: pod-delete
spec:
components:
env:
# randomness enables iterations at random time interval
# it supports true and false value
- name: RANDOMNESS
value: "true"
- name: TOTAL_CHAOS_DURATION
value: "60"
# it will select a random interval within this range
# if only one value is provided then it will select a random interval within 0-CHAOS_INTERVAL range
- name: CHAOS_INTERVAL
value: "5-10"