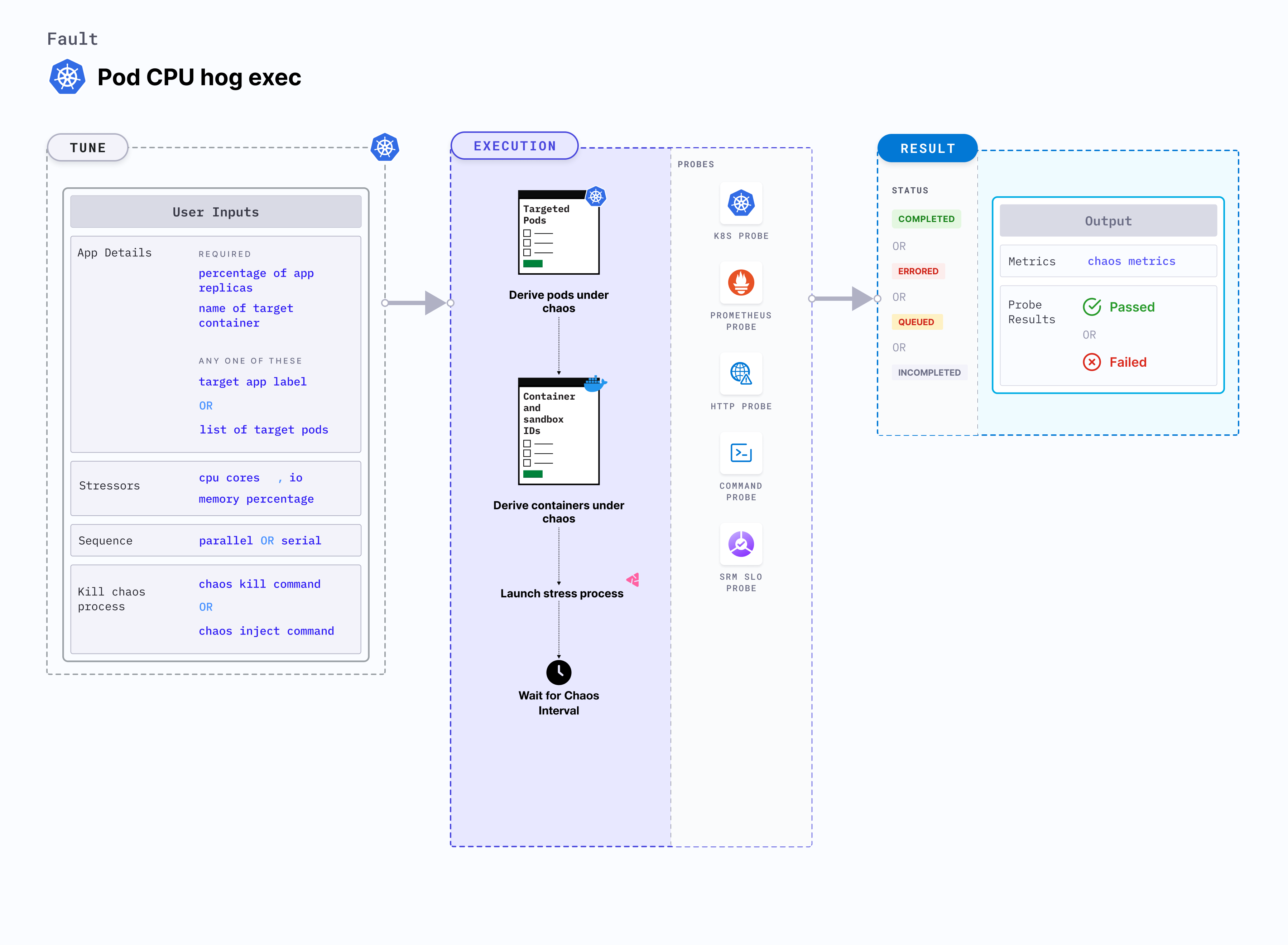
Pod CPU hog exec
Pod CPU hog exec is a Kubernetes pod-level chaos fault that consumes excess CPU resources of the application container. This fault applies stress on the target pods by simulating a lack of CPU for processes running on the Kubernetes application. This degrades the performance of the application.
Use cases
CPU hog exec:
- Simulates conditions where the application pods experience CPU spikes due to expected (or undesired) processes thereby testing the behaviour of application stack.
- Verifies metrics-based horizontal pod autoscaling as well as vertical autoscale, that is, demand based CPU addition.
- Facilitates scalability of nodes based on the growth beyond budgeted pods.
- Verifies the autopilot functionality of cloud managed clusters.
- Verifies multi-tenant load issues, that is, when the load increases on one container, this does not cause downtime in other containers.
Prerequisites
- Kubernetes > 1.16 is required to execute this fault.
- The application pods should be in the running state before and after injecting chaos.
Optional tunables
| Tunable | Description | Notes |
|---|---|---|
| CPU_CORES | Number of CPU cores subject to CPU stress. | Default: 1. For more information, go to CPU cores |
| TOTAL_CHAOS_DURATION | Duration for which to insert chaos (in seconds). | Default: 60 s. For more information, go to duration of the chaos |
| NODE_LABEL | Node label used to filter the target node if TARGET_NODE environment variable is not set. | It is mutually exclusive with the TARGET_NODE environment variable. If both are provided, the fault uses TARGET_NODE. For more information, go to node label. |
| TARGET_PODS | Comma-separated list of application pod names subject to pod CPU hog. | If not provided, the fault selects the target pods randomly based on the provided appLabels. For more information, go to target specific pods |
| TARGET_CONTAINER | Name of the target container under stress. | If this value is not provided, the fault selects the first container of the target pod. For more information, go to target specific container |
| PODS_AFFECTED_PERC | Percentage of total pods to target. Provide numeric values. | Default: 0 (corresponds to 1 replica). For more information, go to pods affected percentage |
| CHAOS_INJECT_COMMAND | Command to inject CPU chaos. | Default: md5sum /dev/zero. For more information, go to chaos inject command |
| CHAOS_KILL_COMMAND | Command to kill the chaos process. | Defaults to kill $(find /proc -name exe -lname '*/md5sum' 2>&1 | grep -v 'Permission denied' | awk -F/ '{print $(NF-1)}'). Another useful one that generally works (in case the default doesn't) is kill -9 $(ps afx | grep "[md5sum] /dev/zero" | awk '{print $1}' | tr '\n' ' '). In case neither works, please check whether the target pod's base image offers a shell. If yes, identify appropriate shell command to kill the chaos process. For more information, go to chaos kill command |
| RAMP_TIME | Period to wait before injecting chaos (in seconds). | For example, 30 s. For more information, go to ramp time |
| LIB_IMAGE | Image used to inject chaos. | Default: chaosnative/chaos-go-runner:main-latest. For more information, go to image used by the helper pod. |
| SEQUENCE | Sequence of chaos execution for multiple target pods. | Default: parallel. Supports serial and parallel. For more information, go to sequence of chaos execution |
CPU cores
Number of CPU cores to target. Tune it by using the CPU_CORE environment variable.
The following YAML snippet illustrates the use of this environment variable:
# CPU cores for the stress
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
appinfo:
appns: "default"
applabel: "app=nginx"
appkind: "deployment"
chaosServiceAccount: litmus-admin
experiments:
- name: pod-cpu-hog-exec
spec:
components:
env:
# CPU cores for stress
- name: CPU_CORES
value: "1"
- name: TOTAL_CHAOS_DURATION
value: "60"
Chaos inject and kill commands
The CHAOS_INJECT_COMMAND and CHAOS_KILL_COMMAND environment variables to set the chaos inject and chaos kill commands, respectively.
Default values CHAOS_INJECT_COMMAND is "md5sum /dev/zero" and CHAOS_KILL_COMMAND is "kill $(find /proc -name exe -lname '*/md5sum' 2>&1 | grep -v 'Permission denied' | awk -F/ '{print $(NF-1)}')"
The following YAML snippet illustrates the use of these environment variables:
# provide the chaos kill, used to kill the chaos process
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
appinfo:
appns: "default"
applabel: "app=nginx"
appkind: "deployment"
chaosServiceAccount: litmus-admin
experiments:
- name: pod-cpu-hog-exec
spec:
components:
env:
# command to create the md5sum process to stress the cpu
- name: CHAOS_INJECT_COMMAND
value: "md5sum /dev/zero"
# command to kill the md5sum process
# alternative command: "kill -9 $(ps afx | grep \"[md5sum] /dev/zero\" | awk '{print$1}' | tr '\n' ' ')"
- name: CHAOS_KILL_COMMAND
value: "kill $(find /proc -name exe -lname '*/md5sum' 2>&1 | grep -v 'Permission denied' | awk -F/ '{print $(NF-1)}')"
- name: TOTAL_CHAOS_DURATION
value: "60"